

第四章 – 4.3 通过selenium 模拟浏览器抓取
4.3 通过selenium 模拟浏览器抓取
在上述的例子中,使用Chrome“检查”功能找到源地址还十分容易。但是有一些网站非常复杂,例如前面的天猫产品评论,使用“检查”功能很难找到调用的网页地址。除此之外,有一些数据真实地址的URL也十分冗长和复杂,有些网站为了规避这些抓取会对地址进行加密,造成其中的一些变量让人摸不着头脑。
因此,这里介绍第二种方法,使用浏览器渲染引擎。直接用浏览器在显示网页时解析HTML,应用CSS样式并执行JavaScript的语句。
这方法在爬虫过程中会打开一个浏览器,加载该网页,自动操作浏览器浏览各个网页,顺便把数据抓下来。用一句简单而通俗的话说,使用浏览器渲染方法,爬取动态网页变成了爬取静态网页。
我们可以用Python的selenium库模拟浏览器完成抓取。Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真正的用户在操作一样。
4.3.1 selenium 的安装与基本介绍
selenium的安装非常简单,和其他的Python 库一样,我们可以用pip 安装。
pip install selenium
selenium的脚本可以控制浏览器进行操作,可以实现多个浏览器的调用,包括IE(7, 8, 9, 10, 11),Firefox,Safari,Google Chrome,Opera等。最常用的是 Firefox,因此下面的讲解也以Firefox为例,在执行之前你需要安装Firefox浏览器。
首先,我们打开使用 selenium 打开浏览器和一个网页,以下是代码:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
运行之后,发现程序报错,错误为:
selenium.common.exceptions.WebDriverException:Message: ‘geckodriver’ executable needs to be in PATH.
在selenium之前的版本中,这样做是不会报错的,但是Selenium新版无法运行。我们要下载geckodriver,可以到https://github.com/mozilla/geckodriver/releases 下载相应操作系统的geckodriver,这是一个压缩文件,解压后可以放在桌面,如C:\Users\santostang\Desktop\geckodriver.exe。最后的代码如下:
from selenium import webdriver
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
运行后,代码会打开“Hello World”这篇文章的页面。如下图所示:
4.3.2 selenium的实战案例
为了演示Selenium是怎么工作的,我们这里把前面用Chrome“检查”方法获取网页真实地址,然后爬取博客文章评论的网页爬虫方法,写成Selenium的版本。
由于Selenium使用浏览器渲染,因此,那些评论数据已经渲染到了HTML代码中。我们可以使用Chrome“检查”方法,定位到元素位置。
步骤一:找到评论的HTML代码标签。使用Chrome打开该文章页面,右键点击页面,打开“检查”选项。按照第二章的方法,定位到评论数据。如下图所示:可以看到该数据的标签为
。
步骤二:尝试获取一条评论数据。在原来打开页面的代码数据上,我们可以使用以下代码,获取第一条评论数据。在下面代码中,driver.find_element_by_css_selector是用CSS选择器查找元素,找到class为’reply-content’的div元素;find_element_by_tag_name则是通过元素的tag去寻找,意思是找到comment中的p元素。最后,再输出p元素中的text文本。
comment = driver.find_element_by_css_selector('div.reply-content')
content = comment.find_element_by_tag_name('p')
print (content.text)
运行上述代码,我们得到的结果是错误:“Message: Unable to locate element:
div.reply-content”。这究竟是为什么呢?
步骤三:我们可以在 jupyter 中键入driver.page_source
找到为什么没有定位到评论元素,通过排查我们发现,原来代码中的 JavaScript 解析成了一个 iframe,
<
iframe title=”livere” scrolling=”no”…>也就是说,所有的评论都装在这个框架之中,里面的评论并没有解析出来,所以我们才找不到div.reply-content元素。这时,我们需要加上对 iframe 的解析。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment = driver.find_element_by_css_selector('div.reply-content')
content = comment.find_element_by_tag_name('p')
print (content.text)
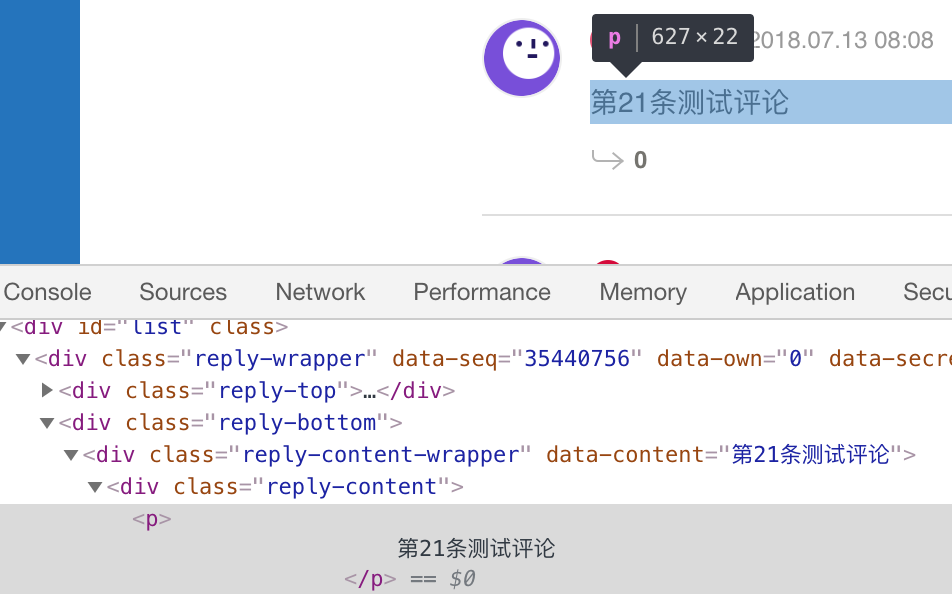
运行上述代码,我们可以得到最上面的一条评论:“第21条测试评论”。
4.3.3 selenium获取文章的所有评论
上一节只是获取了一条评论,如果要获取所有评论,就需要脚本程序能够自动单击“+10 查看更多”。这样才能够把所有评论显示出来。
因此,我们需要找到“+10 查看更多”的元素地址,然后让Selenium模拟单击并加载评论。具体代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
driver.implicitly_wait(20) # 隐性等待,最长等20秒
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
time.sleep(5)
for i in range(0,3):
# 下滑到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
load_more = driver.find_element_by_css_selector('button.more-btn')
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
代码的前面部分和之前一样,用来打开该文章页面。第一个for循环用来把所有的评论加载出来。首先,把页面用driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”)下滑到页面底部,这样才会出现“+10查看更多”的元素。
接下来,就需要用driver.switch_to.frame()解析iframe,找到使用driver.find_element_by_css_selector(‘button.more-btn’)找到该元素,然后使用.click()方法模拟单击并加载,那么就会加载多10个评论。因为解析iframe后,下滑的代码就用不了了,所以又要用driver.switch_to.default_content() 转回去成本来的未解析iframe。使用time.sleep(2)可以让代码等待2秒钟,让它来加载评论。
用for循环加载多3页的评论之后,那么就可以提取评论了。
在加载出前面几页的评论之后,就可以像之前的代码一样,把评论提取出来。不过,首先还是要用driver.switch_to.frame()解析下已经转回去的iframe。之后才可以用driver.find_elements_by_css_selector提取评论。
运行完成后,打印出来的结果是:

其实,selenium选择元素的方法有很多,具体如下所示:
- find_element_by_id:通过元素的id选择,例如:driver.find_element_by_id(‘loginForm’)
- find_element_by_name:通过元素的name选择,driver.find_element_by_name(‘password’)
- find_element_by_xpath:通过xpath选择,driver.find_element_by_xpath(“//form[1]”)
- find_element_by_link_text:通过链接地址选择
- find_element_by_partial_link_text:通过链接的部分地址选择
- find_element_by_tag_name:通过元素的名称选择
- find_element_by_class_name:通过元素的id选择
- find_element_by_css_selector:通过css选择器选择
有时候,我们需要查找多个元素。在上述例子中,我们就查找了所有的评论。因此,也有对应的元素选择方法,就是在上述的element后加上s,变成elements。
– find_elements_by_name
– find_elements_by_xpath
– find_elements_by_link_text
– find_elements_by_partial_link_text
– find_elements_by_tag_name
– find_elements_by_class_name
– find_elements_by_css_selector
其中xpath和css_selector是比较好的方法,一方面比较清晰,另一方面相对其他方法定位元素比较准确。
除此之外,我们还可以使用selenium操作元素方法实现自动操作网页。常见的操作元素方法如下:
– clear 清除元素的内容
– send_keys 模拟按键输入
– click 点击元素
– submit 提交表单
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录
上述代码中,是一个自动登录程序中截取的一部分。从代码中可以看到,我们可以用selenium操作元素的方法,对浏览器中的网页进行各种操作,包括登录。
除此之外,selenium除了鼠标简单的操作,还可以实现复杂的双击,拖拽等操作。此外,它还可以获得网页中各个元素的大小,甚至还可以进行模拟键盘的操作。由于篇幅有限,有兴趣的读者,可以到selenium的官方文档查看:http://selenium-python.readthedocs.io/index.html
4.3.4 Selenium的高级操作
使用Selenium和使用浏览器“检查”方法爬取动态网页相比,Selenium因为要把整个网页加载出来,再开始爬取内容,速度往往较慢。
因此在实际使用当中,如果使用浏览器“检查”功能进行网页的逆向工程不复杂的话,最好使用浏览器“检查”功能方法。不过,也有一些方法可以用Selenium控制浏览器的加载的内容,从而加快Selenium的爬取速度。常用的方法有:
1. 控制CSS的加载
2. 控制图片文件的显示
3. 控制JavaScript的执行
1.控制CSS。因为抓取过程中仅仅抓取页面的内容,CSS样式文件是用来控制页面的外观和元素放置位置的,对内容并没有影响,所以我们可以限制网页加载CSS,从而减少抓取时间。其代码如下:
# 控制 css
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
driver = webdriver.Firefox(firefox_profile=fp, executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
在上述代码中,控制css的加载主要用fp = webdriver.FirefoxProfile()这个功能。设定不加载css,使用fp.set_preference(“permissions.default.stylesheet”,2)。之后使用webdriver.Firefox(firefox_profile=fp)就可以控制不加载css了。运行上述代码,得到的页面如下所示。
2.限制图片的加载。如果不需要抓取网页上的图片,最好可以禁止图片加载,限制图片的加载可以帮助我们极大地提高网络爬虫的效率。因为网页上的图片往往较多,而且图片文件相对于文字、CSS、JavaScript等其他文件都比较大,所以加载需要较长时间。
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)
driver = webdriver.Firefox(firefox_profile=fp, executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
与限制css类似,限制图片的加载可以用fp.set_preference(“permissions. default.image”,2)。运行上述代码,得到的页面如图所示。

3.控制JavaScript的运行。如果需要抓取的内容不是通过JavaScript动态加载得到的,我们可以通过禁止JavaScript的执行来提高抓取的效率。因为大多数网页都会利用JavaScript异步加载很多内容,这些内容不仅是我们不需要的,它们的加载还浪费了时间。
# 限制 JavaScript 的执行
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
driver = webdriver.Firefox(firefox_profile=fp, executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
那么这三种方法,哪一种最节省时间呢?通过对上述三种方法的测试,尝试加载博客的主页50次,并对于加载时间取平均值。我们发现三种方法各自加载所需的时间,如下表所示:
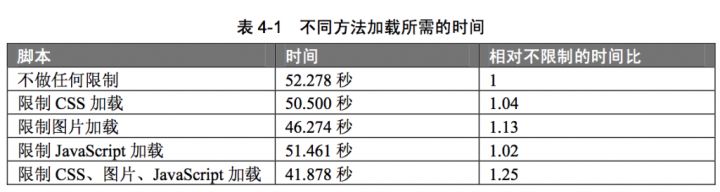
通过上述结果,我们发现 3 种限制方法都能使爬虫加载网页的速度有所加快,其中全部限制对于加载速度的提升效果最好。由于 3 种方法的时间相差并不是很多,再加上网络环境和随机变量的原因,因此我们并不能肯定哪种方法更好。具体的加载速度提升还得看相应的网页,若网页的图片比较多,则限制图片的加载肯定效果很好。 如果能够限制,那么最好限制多种加载,这样的效果最好。
第四章其他章节请查看
第四章:动态网页抓取 (解析真实地址 + selenium)
4.2 解析真实地址抓取
4.3 通过selenium 模拟浏览器抓取

