

第四章 – 4.2 解析真实地址抓取
由于网易云跟帖停止服务,现在已经在此处中更新了新写的第四章。请参照文章:
4.2 解析真实地址抓取
虽然数据并没有出现在网页源代码中,我们也可以找到数据的真实地址,请求这个真实地址也可以获得想要的数据。这里用到浏览器的“检查”功能。
下面以我博客的“Hello World”文章为例,目标是抓取文章下的所有评论。文章网址为: http://www.santostang.com/2018/07/04/hello-world/
步骤一:打开“检查”功能。用Chrome浏览器打开“Hello World”文章。右键页面任意位置,在弹出的对话框中,点击“检查”选项。得到如下图所示的对话框。
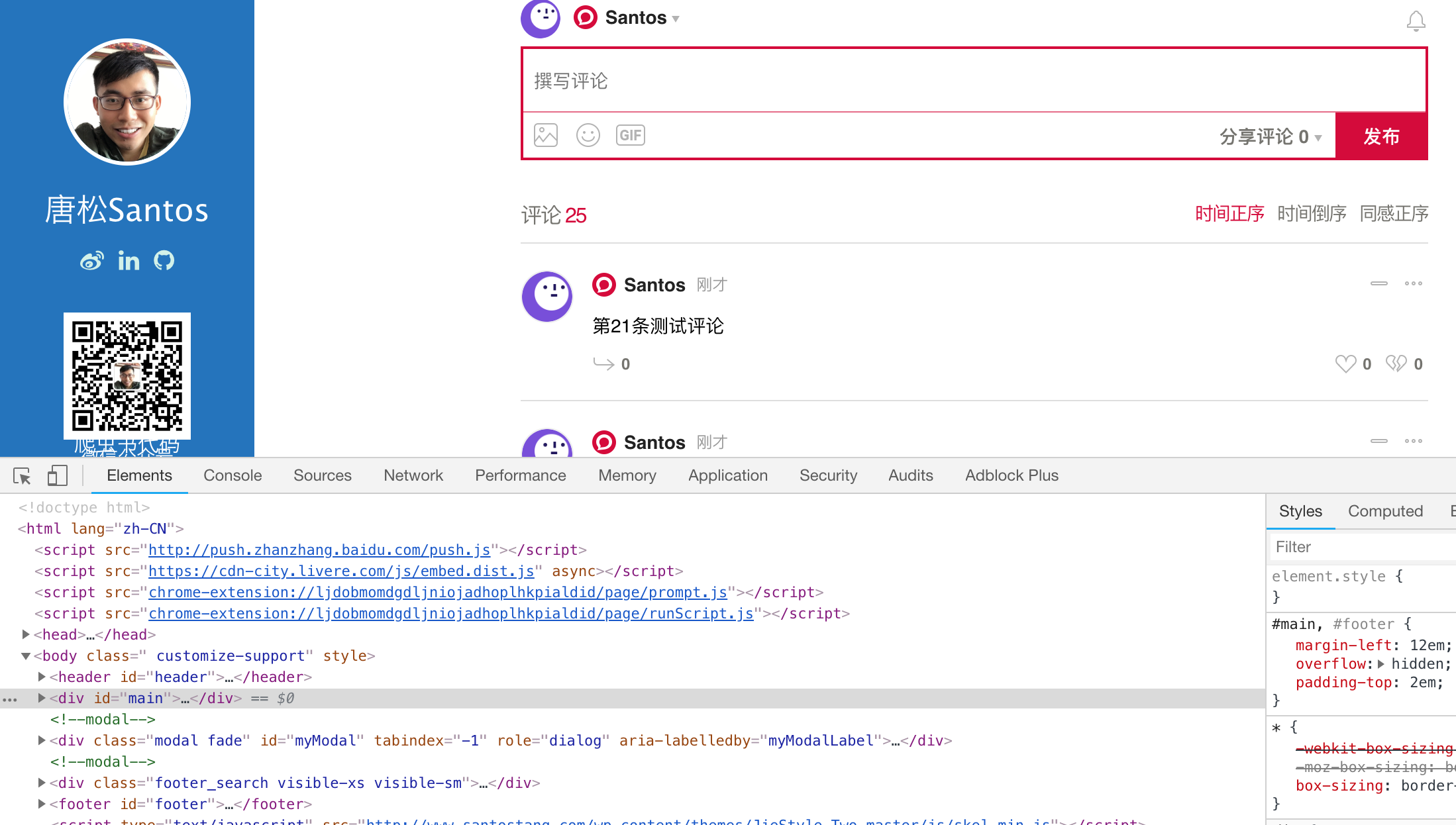
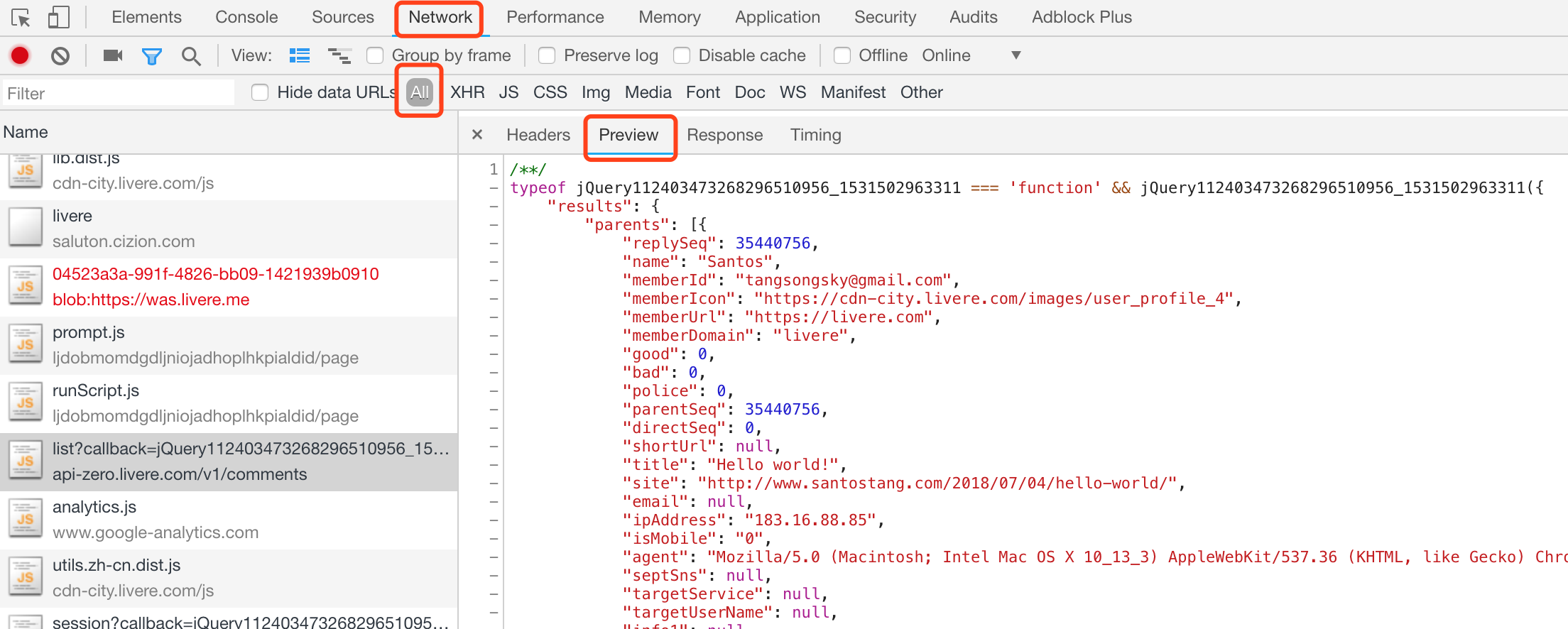
步骤二:找到真实的数据地址。点击对话框中的Network,然后刷新网页。此时,Network 会显示浏览器从网页服务器中得到的所有文件,一般这个过程称之为“抓包”。因为所有文件已经显示出来,所以我们需要的评论数据一定在其中。
一般而言,这些数据可能以 json 文件格式获取。所以,我们可以在Network中的 All找到真正的评论文件“list?callback=jQuery11240879907919223679”,其地址为: “https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963313” 。点击 Preview 即可查看数据。
步骤三:爬取真实评论数据地址。既然找到了真实的地址,我们就可以直接用requests请求这个地址,获取数据。代码如下如所示:
import requests
link = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963313"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print (r.text)
运行上述代码获得的结果为:

综上所述,如果要爬取类似淘宝网评论这种用AJAX加载的网页的话,从网页源代码中是找不到想要的数据的。需要用浏览器的审查元素,找到真实的数据地址。然后爬取真实的网站。
步骤三:从 json数据中提取评论。上述的结果比较杂乱,但是它其实是 json 数据,我们可以使用 json 库解析数据,从中提取我们想要的数据。
import json
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
首先,我们需要使用json_string[json_string.find(‘{‘}:-2)], 仅仅提取字符串中符合json格式的部分。然后,使用 json.loads 可以把字符串格式的响应体数据转化为 json 数据。然后,利用 json 数据的结构,我们可以提取到评论的列表comment_list。最后再通过一个 for 循环,提取其中的评论文本,并输出打印。
输出的结果为:

上述的教学,只是爬取文章的第一页评论,十分简单。其实,我们经常需要爬取所有页面,如果我们还是用人工一页页地翻页,找到评论数据的地址,就十分费力了。因此,下面将介绍网页 URL地址的规律,并用for循环爬取,就会非常轻松。
例如:刚刚的文章第一页评论的真实地址是
https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&offset=1&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316
如果我们继续点击“查看更多”,从“审查元素”中可以发现第二页的地址:
https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&offset=2&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316
如果我们对比上面的两个地址,可以发现 URL 地址中有两个特别重要的变量,offset 和 limit,稍微理解一下可以知道,limit 代表的是每一页评论数量的最大值,也就是说,这里每一页评论最多显示30条;offset 代表的是第几页,第一页 offset 为0,第二页为1,那么第三页 offset 会是3。
因此,我们只需在URL中改变 offset 的值,便可以实现换页。以下是实现的代码:
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&offset="
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
在上述代码,函数single_page_comment(link)是之前爬取一个评论页面的代码,现在放入函数中,方便多次调取。另外,我们使用一个 for 循环,分别抓取第一页和第二页,在生成最终真实的URL地址后,调用函数抓取。
运行完代码,得到的结果是:

第四章其他章节请查看
第四章:动态网页抓取 (解析真实地址 + selenium)
4.2 解析真实地址抓取
4.3 通过selenium 模拟浏览器抓取

